「The Cherno-C++」学习笔记三(67-90)

B站up神经元猫翻译版:https://www.bilibili.com/video/BV1uy4y167h2
前言
C++因为其优异的性能,是游戏开发中最为常用的语言之一,目前的Unity与Unreal两大商用引擎的内核都是采用C++进行编写,作为一个有志于成为游戏开发者的人,这种语言怎么能不学一学呢?
本文基于油管著名博主,曾任职于EA的The Cherno的C++系列视频,The Cherno作为寒霜引擎的核心开发人员之一,对C++有着非常独到而深刻的理解
这些笔记记录了我通过The Cherno的系列视频学习C++的一些知识点与理解,希望对你有帮助😉
第一章(1-33):https://hmxs.games/posts/1001/
第二章(34-66):https://hmxs.games/posts/1002/
第三章(67-99):https://hmxs.games/posts/1003/
联合体(67)
联合体在使用上有点类似类或结构体,但区别是,同一时间一个联合体内只能有一个成员,即联合体的中的所有成员都共用一片内存空间
1 | union A |
在上面这个联合体中,如果你改变a的值,b也同样会被改变
在类型双关中的应用:
union可以被用来方便地实现上一章讲到的类型双关
1 | int main() |
在上面这个例子中对a和b的赋值和访问会因为联合体的特性自动地实现类型双关
1 | struct Vector2 |
在上面这个例子中,我们可以通过4个int或2个Vector2变量来表示Vector4,并且数据是互通的,这也是联合体的妙用
虚析构函数(68)
顾名思义,虚析构函数便是虚函数和析构函数的结合体,但其在一些情况下非常重要
1 | class Base |
在上面这个例子中,我们可以发现,在创建与销毁子类时,父类的构造与析构函数会在最开始与最后被调用
但当我们通过父类的指针访问一个子类对象时,所有构造函数都被正确调用了,但缺只有父类的析构函数被调用了,子类的析构函数没有被调用,这可能会导致内存泄露
而我们可以通过虚析构函数来解决这一问题,与普通虚函数不同的是,虚析构函数所做的并不是“替换”,而是“加上”
1 | class Base |
我们只需要为基类的析构函数加上virtual即可
如果用基类指针来引用派生类对象,那么基类的析构函数必须是 virtual 的,否则 C++ 只会调用基类的析构函数,不会调用派生类的析构函数。
类型转换(69)
C++作为一种强类型语言,其类型的存在是强制性的,我们不能突兀地直接转变某一对象的类型,我们必须进行显式或隐式的类型转换,而在C++中我们可以使用C风格或C++风格的语法进行类型转换
1 | // 隐式类型转换 |
上面是隐式与C风格的显示类型转换,其语法非常简单直观
而在C++中,我们也可以使用内置的一系列cast函数来实现类型转换,一共有4种主要的cast函数:static_cast、reinterpret_cast、dynamic_cast、const_cast
需要注意的是,cast函数可以实现的功能使用C语言风格的类型转换也一样可以,它们并没有实现什么新功能,只是添加了一些语法糖到你的代码中
C++设置这么多cast的目的:除了一些编译时的额外特性,还可以帮助我们在代码库中快速地找到我们在什么地方使用了类型转换,而C语言风格的类型转换则非常难以定位,并且在我们尝试进行类型转换时,也可以帮助我们避免一些意外错误,比如类型不兼容
下面是一个关于dynamic_cast的实例:
dynamic_cast在类型转换时会进行编译时检查,如果转换不成功,其会将对象赋值为空
1 | class Base |
我们可以使用dynamic_cast自动进行类型转换时的安全检查
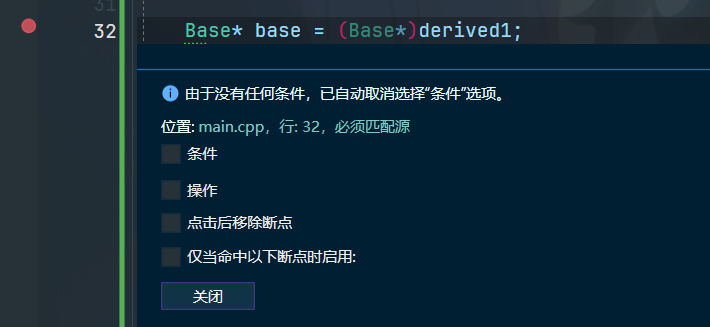
条件与操作断点(70)
条件与操作断点可以被应用与更加复杂的调试场景
条件断点可以让断点只在特定条件下触发
操作断点则允许我们在碰到断点时采取某种动作,如打印一些东西到控制台
条件与操作断点的优势在于其可以在不用更改任何代码的情况下,在运行时进行debug,这对我们的开发效率有很大的提升
右击断点的小红点,点击条件/操作,即可调出条件与操作断点界面,如下图所示:
这是一个简单而十分强大地功能,特别是在我们需要调试一些较为大型的程序时
但同时,需要注意的是,附加调试程序是十分耗费性能的
安全问题与如何授权(71)
C++中的安全问题一直争议不休,有人说我们应该拥抱智能指针,抛弃原始指针,而也有人说,智能指针有着严重的开销问题,是男人就用原始指针!
而Cherno对此的态度是:没有绝对的标准答案
对于生产环境而言,我们绝对应该使用智能指针,这会大大降低我们出错的概率,也会提高协作的效率
对于学习和了解而言,使用原始指针可以帮助我们更好地理解指针的工作原理,因为智能指针实际上也只是原始指针的一层封装
当然,如果你需要定制的话,也可以使用自己写的智能指针
预编译头文件(72)
预编译头文件实际上是让你抓取一堆头文件,并将它们转换为“编译器格式”,使得我们不比一遍又一遍地读取这些头文件
在实际地代码编写中,我们往往会include一些头文件,而每当我们对程序进行修改时,这些头文件都需要被从头开始重新编译,这会大大拖慢编译的速度
而预编译头文件可以预先将这些头文件编译为二进制形式储存,加快之后编译的速度
但需要注意的是,不要讲会经常变更的东西放入预编译头文件中,这会适得其反,是本末倒置的行为
那么我们应该如何创建一个预编译头文件呢?
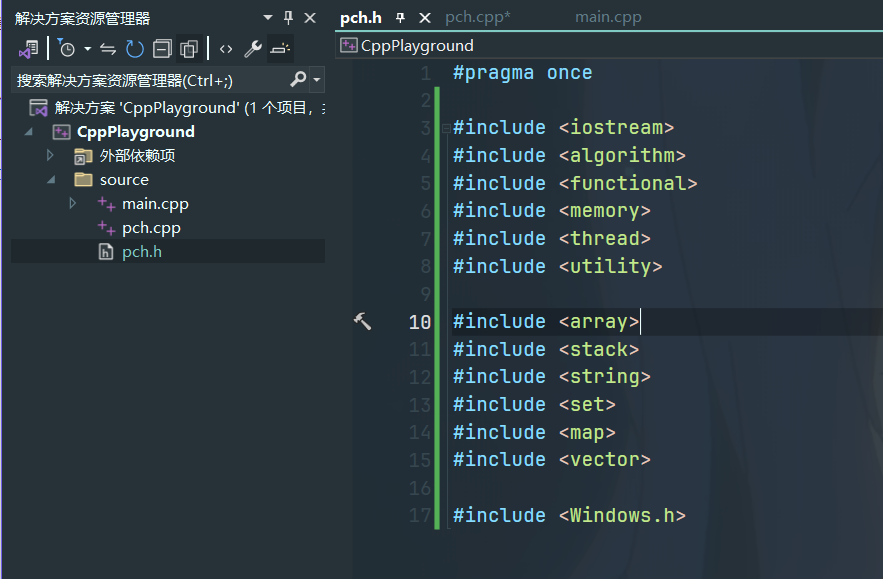
如图所示,我们要预编译上述pch.h头文件
在VS中,我们需要创建一个空.cpp文件,其中只包含需要预编译的头文件,如下图所示
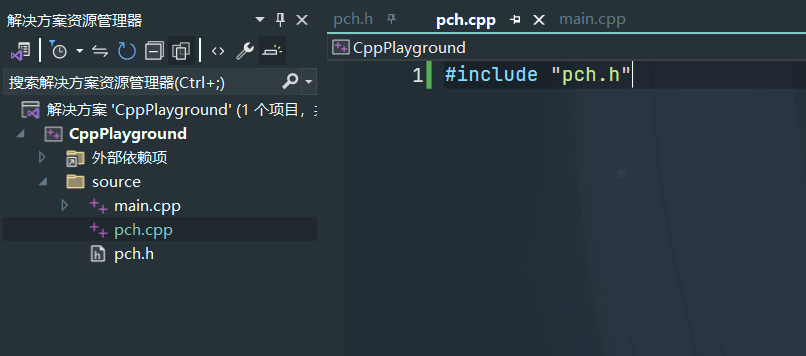
之后我们便可以右键刚刚创建的.cpp文件,点击属性->C/C++->预编译头,将预编译头选项设置为创建
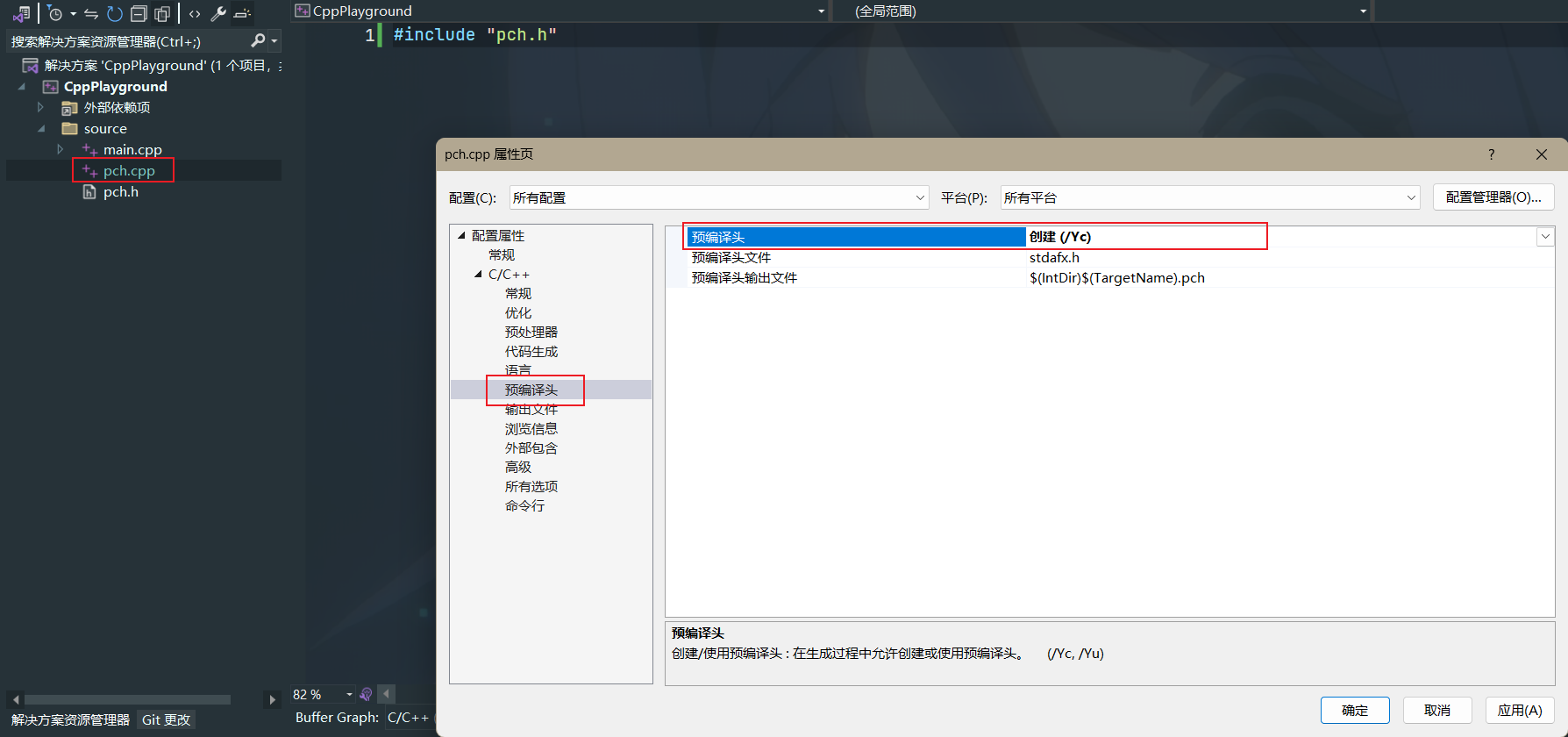
最后我们将项目设置中的同样位置的预编译头选项改为使用,并将预编译头文件改为对应头文件名即可
除非你的项目极其小,否则都应该使用预编译头文件,这会大大加快你的编译速度
dynamic_cast(73)
dynamic_cast是在69章类型转换中提到过的一种C++风格的类型转换函数其专门用于沿继承层级结构进行的强制类型转换,如果我们想把一个基类强转为派生类,或从派生类强转为基类,那么便可以使用
dynamic_cast
如,我们有一个Entity基类,Player与Enemy类都派生自Entity,我们想将一个Entity实例强转为Player,但这一实例也有可能是Enemy,如果这时我们尝试去对Player独有的数据进行访问和更改,就很可能会引发问题,而使用dynamic_cast进行这种类型的强转时,如果发生了上述情况,dynamic_cast会中断转换并直接返回Null
1 | class Entity |
dynamic_cast的运行机制
dynamic_cast实现运行时类型检查是因为其储存了运行时类型信息(RTTI:Runtime Type Information),其储存了我们的所有类型的运行时类型信息,这显而易见地会增加开销,但它可以让你实现类似动态类型转换的事情,在使用时需要进行取舍
基准测试(74)
基准测试往往被用于测量一段特定代码的性能,测试方法多种多样,如之前写过的作用域计时便可以用于基准测试
作用域计时器:
1 | class Timer |
只需要在对应作用域创建一个Timer实例即可实现自动计时
1 | int main() |
但需要注意的是,我们需要确保我们进行基准测试的代码应和实际运行情况相同
如,在VS中在Debug和Release模式下运行代码会有很大不同,在Release模式下编译器会自动地对代码进行优化
下面是一个基准测试的实际应用:
使用基准测试进行不同智能指针的性能测试
1 | int main() |
结构化绑定(75)
结构化绑定是C++17引入的新机制,其可以帮助我们更好地处理多返回值
在之前的52章如何处理多返回值时,有讲到可以使用std::tuple/std::pair来进行处理,但这是一种不够清晰,且较为繁琐的传值方法,我们很少使用它们
但这种情况在结构化绑定的加入后得以改善
下面是一个例子:
1 | std::tuple<std::string, int> CreatePerson() |
以上函数会返回一个元组,而当我们想要处理上述函数的返回值时,我们往往只能使用get函数或tie函数,如下所示
1 | std::string name; |
其中使用tie或许会更加简洁,但总的来说都并不方便,不如使用结构体进行处理
而结构化绑定大幅降低了代码的复杂度,我们不再需要tie和get,如下所示即可完成数据的提取
1 | auto [name, age] = CreatePerson(); |
简洁而高效,如果我们只需要处理少数几次某一多类型返回值,那么使用结构化绑定会成为我们的最优选
但需要注意的是,此特性只在C++17或更高版本中有效,在使用前需要确认好正在使用的版本
如何处理Optional数据(76)
std::optional是C++17引入的新类,用于处理那些可能存在,也可能不存在的数据,或者是一种我们不确定的类型(有点类似C#中的?)
下面是一个使用例:
1 | std::string ReadFileAsString(const std::string& file_path) |
对于上面这个读取文件的函数而言,在之前的C++中,要判断“文件是否被成功读取到了”是较为麻烦的
一个实现方法是从外部传入一个bool值引用,再在函数内部进行改变,但是这样显然不是很优雅
而std::optional可以较为方便地解决这一问题
1 | std::optional<std::string> ReadFileAsString(const std::string& file_path) |
我们只需将返回值加上optional,之后即可在外部进行判断
1 | std::optional<std::string> data = ReadFileAsString("data.txt"); |
同时我们也可以方便地提起其中的值
1 | std::string string_data; |
而value_or()函数可以自动为被判定为空的optional值设定默认值,如下所示
1 | string_data = data.value_or("File Did Not Exist"); |
单一变量存放多类型数据(77)
std::variant是C++17中引入的新类,它可以让我们在创建变量时不用处理变量的确切数据类型
1 | std::variant<std::string, int> data; |
std::variant与union可以起到的作用有些类似,他们各有优劣
union的内存大小由其中最大的类型决定,而std::variant则比较类似class,其内存大小等于你声明的所有类型的内存总和,从这一角度上看,union的空间性能更好
但与之相对的std::variant拥有更好的安全性,其是类型安全的
如何储存任意类型的数据(78)
std::any是C++17中引入的新类,它可以储存任意类型的数据
1 | std::any data; |
正如any的名字一样,std::any可以存储所有类型,这看起来便于编写,会比上一章讲到的std::variant方便很多,但这并不一定是优点,any的任意属性会给我们带来很多意料之外的麻烦
1 | std::any data; |
如上面这段代码,看起来十分合理,但是实际上运行则会报错,因为字面量"Hmxs"的类型实际上是const char[5],而我们将其看做了std::string,any_cast并不会帮我们进行隐式类型转换,但差不多的代码使用std::variant则完全不会有问题,因为其是类型安全的
而除此之外,std::any还存在一定程度的内存问题,当我们将any类型的变量赋值为内存较小的类型如int、float时,其运行机制与variant几乎一样,但当我们将其定义为较大的类型时,其会自动地进行动态内存分配,而对性能并不是什么好事
总而言之,就目前而言
any几乎没有比较好的应用场景,而为了我们的C++程序能更好地跑起来,我们应该尽量避免使用它
如何让C++运行地更快(79)
现代硬件往往是可以进行并行运算的,这意味着你可以在同一时间并行执行指令,使用多线程可以大幅提高程序运行的速度,但多线程带来的程序调度问题也是十分复杂的
在C++11中,
std::async被引入帮助我们实现程序的多线程化
如何让字符串更快(80)
C++的字符串实际上非常慢,而我们可以做一些事情让它们能被更快地处理
std::string的主要问题之一,可能就是字符串格式化以及字符串操作,因为它们都需要进行内存分配
下面的代码通过重载new运算符的方式揭示了其会进行的内存分配
1 | static uint32_t count = 0; |
运行后我们可以看到std::string调用了new进行了1次内存分配
同时使用substr()这类对字符串进行操作的函数也会进行内存分配
而解决它们的方法便是C++17中引入的std::string_view或自己对字符串进行包装
std::string_view是一个指向现有字符串内存的指针,其就像一个观察字符串的窗口,通过它我们便可以减少进行字符串操作时发生的内存分配
1 | std::string name = "hmxs"; |
这样一来内存分配便被减少了
而不使用std::string使用const char*则可以完全不需要内存分配
可视化基准测试(81)
在之前的第74章基准测试中,我们了解了使用Timer类与控制台进行输出的基准测试方法,如下所示
1 | void Function1() |
只需要在对应作用域内声明Timer变量即可
但这种方法有时比较麻烦,在大量控制台输出中寻找那个基准测试数据并不是什么很好的体验
这时候可视化就可以出场了,而我们将使用Edge/Chrome进行可视化基准测试
我们只需要在浏览器的地址栏输入edge://tracing(Chrome则为chrome://tracing)即可进入可视化页面
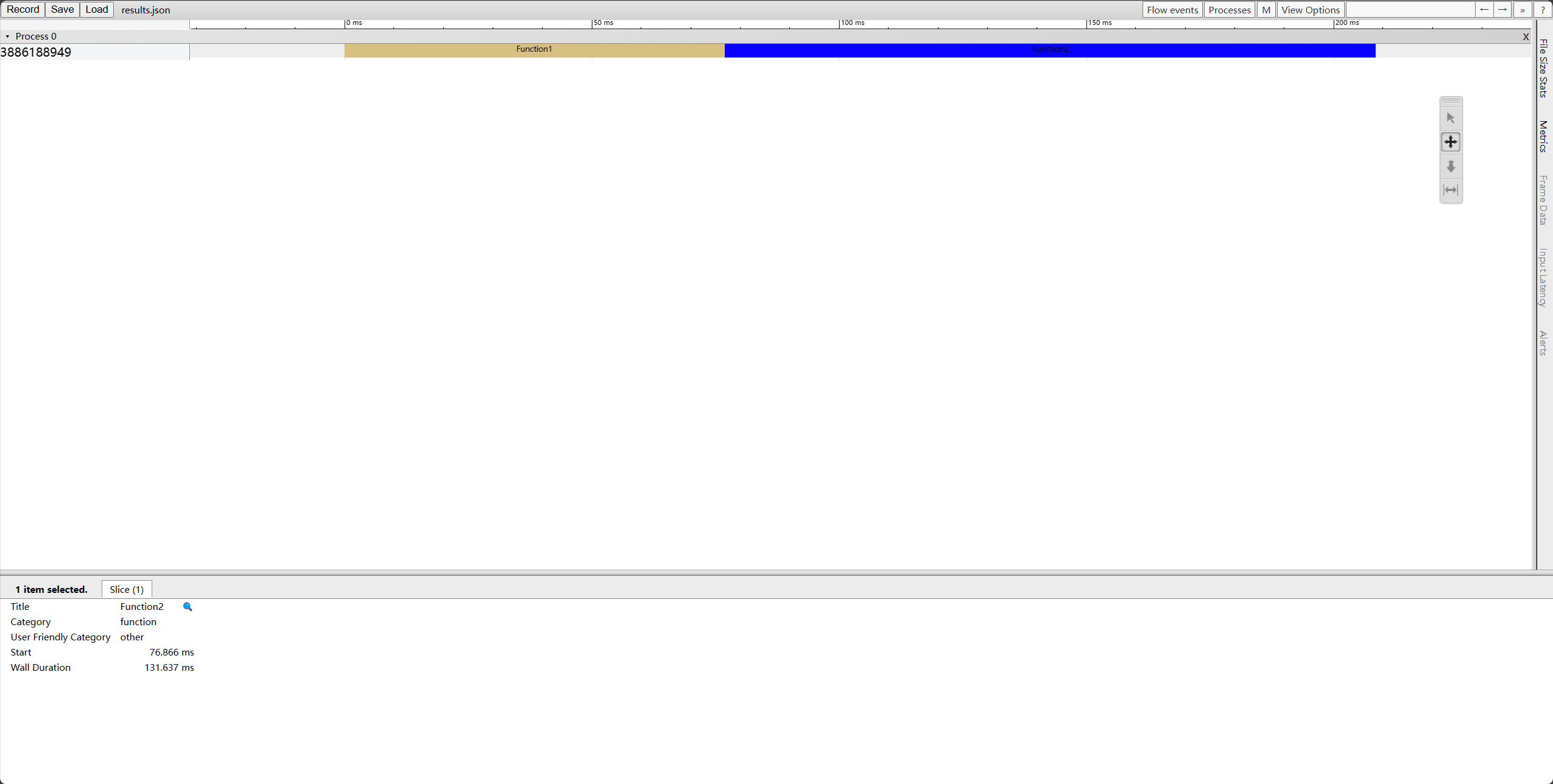
这个页面接受一个.json文件,而我们需要做的便是输出一个符合要求的json文件
使用流输出代码根据规定格式输出即可获得json文件,cherno为我们编写了流输出程序https://gist.github.com/TheCherno/31f135eea6ee729ab5f26a6908eb3a5e
1 | void Function1() |
如此我们便得到了可以使用的json文件,将其拖入上述网站即可获得可视化结果
单例模式(82)
单例模式在C#与Java中会经常被提到,这是一种非常基础的设计模式,其保证了某一类只能被实例化一次,且可以被全局调用
而在C++中,因为C++的灵活性,其实我们并不需要使用类来组织一切,一个全局变量/函数就能实现单例的效果,那么单例在C++中的意义是什么呢?我们可以用更加灵活的眼光看待C++中的单例
C++中的单例只是一种组织一堆全局变量和静态函数的方式,可以起到类似命名空间的效果
C++单例的基础实现
1 | class Singleton |
上述实现需要在外部声明instance,比较麻烦,而我们可以采用下面的写法简化代码
1 | class Singleton |
实际上我们使用命名空间可以达到差不多的效果(除了不能赋值以外),而使用类来对代码进行组织或许会更加有条理
小字符串优化(83)
C++字符串的字符串的慢众所周知,因为其总是倾向于去进行堆内存的分配;但这并不绝对,当我们定义的字符串小于一定长度时,其便不会进行堆内存的分配了
在VS19中,这个值是15,即当我们定义的字符串小于等于15个字符时,其便不会进行内存分配了
跟踪内存分配的简单方法(84)
内存总是程序的重中之重,或许在当代计算机硬件的高速发展下,内存的使用已不再那么捉襟见肘,但对于内存使用仍是我们需要关注的
我们可以对全局的new与delete操作符进行重载+断点+检查内存堆栈的形式简单地检查每一处内存分配与释放的地方
1 | void* operator new(size_t size) |
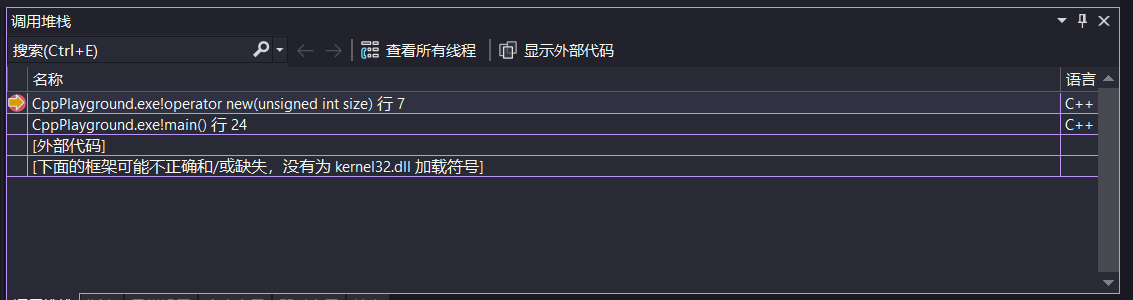
更进一步,我们可以创建一个全局的内存记录器来记录所有分配的内存大小
1 | struct AllocationMetrics |
左值与右值(85)
左值基本上是具有存储属性的对象,其具有地址和值,可以出现在
=的左右两边右值基本上是临时对象,如字面量与表达式,大部分情况下只能出现在
=的右边,不能被赋值左值引用,如
std::string&,只能接受左值,除非加上const右值引用,如
std::sting&&,只能接受右值
左值右值的定义复杂,很难一言以蔽之,纠结于定义反而容易陷入误区,更好的做法是在例子中进行理解
1 | // 返回值为int&类型,是左值引用,所以只能返回左值,即必须是具有存储空间,不能是临时变量 |
1 | std::string name1 = "wzh"; |
1 | // 参数为右值引用,只能传入右值,传入左值会报错,即Print(name)会报错 |
左值右值在进行优化与移动语义时很有用,其也一定程度反应了C++的运行机理
持续集成(86)
持续集成(CI)通常指的是在开发期间持续集成代码的过程,其本质是构建自动化和测试
在多人协作开发的过程中,多名开发者在一起贡献代码的过程中有可能不会在所有平台进行测试,有些只在特定平台会出现的bug有可能就不会被发现,而要求所有开发者为所有平台进行测试成本过于巨大,而持续集成可以帮助我们自动化整个过程,确保代码在所有平台和所有配置下都可以编译
在这集中Cherno推荐了Jenkins来实现持续集成
目前这块内容对我来说并没有很大作用,所以这章先跳过
静态分析(87)
静态分析(Static Analysis)是代码的检查分析器,多一双眼睛检查你的代码总没坏处
其中Cherno推荐了pvs studio,但其中有商业推广的要素
由于不想额外花钱所以这章也先跳过
静态分析工具多种多样,其中也不乏开源免费的工具
参数计算顺序(88)
1 | void Print(int a, int b) |
在上面的代码中,最后会输出什么实际上是不确定的,即未定义行为
C++并没有提供参数计算顺序的规范,所以计算顺序完全根据编译器的实现与C++的版本决定,甚至不同的运行模式也会影响输出的结果
我们应该尽量避免写出这样令人疑惑的代码
移动语义(89)
在C++11之前,如果我们想把一个对象传递给一个函数,并且获得对象的所有权,我们除了拷贝别无选择,我们需要在当前堆栈帧中构造一个一次性对象,然后将它复制到我正在调用的函数中
这并不理想,如果我们的对象比较大,那么这一过程将变得很慢,而这时移动语义便出现了,其允许我们移动对象而不是复制它,以此来提高性能
1 | class String |
在上面这个例子中,如果我们不使用移动语义,那么复制对象几乎无法避免
但我们必须复制对象在这一情景下其实理应是荒谬的,我们的需求为将一个String对象放入Entity中,但我们需要做的却是先在外部创建一个String对象,再将其深拷贝到Entity的String中,为啥我们不能直接将外部创建的String直接移动到Entity中呢?而使用移动语义,我们便得以做到这点
移动语义实质上便是将深拷贝变为浅拷贝,我们需要编写移动构造函数,通过右值引用将对象强行标记为右值,即临时对象,后通过std::move使我们在拷贝时调用移动构造函数,而非复制构造函数
1 | class String |
通过上面的代码,我们便成功避免了多余的复制,其中Entity entity(String("Hmxs"));具体的逻辑是:
- 首先
String("Hmxs")会创建一个临时的String对象,这一对象传入entity的构造函数中 - 因为传入的
String对象是右值,所以会优先进入Entity(String&& name)这一参数为右值引用,并执行name_(std::move(name))的初始化过程
作为右值引用被传入的String对象在进入函数后变为了左值,所以需要使用std::move将其强转为右值引用,才能进入String的移动构造函数
- 之后便进入了
String的移动构造函数中,将entity中的name_指向临时的String对象,之后将临时的String对象置空,即完成了移动过程
因为临时的String对象是右值,且被置空,在语句结束后会自动地进行释放
至此,我们便完成了一次成功的移动语义,cool
std::move与移动赋值操作符(90)
std::move内部的实现是一个static_cast,其会将传入对象的类型强转为对应类型的右值引用形式
std::move是一个优雅的实现,如果我们想要传入右值引用参数,那么我们应该尽量使用它
在上一章中,我们通过编写移动构造函数实现了移动语义,而正如其名字中的构造所言,其是一种类型的构造函数,只有在对象构造时才会被调用
那么如果我们想要对一个已经存在的对象使用移动语义呢?我们应该使用移动赋值操作符
1 | class String |
需要注意的是,我们应该注意分辨移动构造与移动赋值,因为隐式转换的缘故,有时构造函数很容易和赋值相混淆
后记
【The Cherno C++】系列暂时完结啦,后续的91-99因为都比较长且不是我现在需要的知识就先暂时搁置啦,后续再更新吧
一点点跟完了90章的内容,只能说受益匪浅
感谢The Cherno的精品教程,也感谢up主神经元猫的无偿翻译